
The hackathon coding bonanza
R: Hey, our company is conducting a hackathon, you want to team up?
Me: (having college hackathon defeat flashbacks)
R: (looks at me strangely)
Me: Sure! Would love to participate in it, what product are we making?
R: I hoped you would have an idea…
Me: Oh, ideas are in abundance, how difficult could it be?
Proceeds to waste weeks deciding on an idea
We finally decided on making a review management system, (think of Disqus but for product/service reviews so users can collate product specific reviews)
Next we needed USP's...
The product now has a sentiment analysis engine and offensive comment detection

The actual backend 😜
I took up this task. My aim was to make a single endpoint with input as a list of strings and the output being the sentiment analysis (Good/Bad score) and offensive segments score of the input strings.
Environment Setup
Before starting with the model selection, inference setup etc, we need to setup the docker environment. For that I made a docker compose container, since using it is easier than remembering the docker commands to run and build. The docker compose is a simple setup since we have a single service -
docker-compose.yml
version: "3.3"
services:
mlapp:
ports:
- "9000:5000"
image: mlapp
Next we need to add the requirements of the app. Since I have already implemented this I am aware of the requirements, but usually one adds the requirements along the way.
requirements.txt
Flask==2.3.2
huggingface-hub==0.16.4
requests==2.26.0
transformers==4.31.0
detoxify==0.5.0
Dockerfile
# syntax=docker/dockerfile:1
FROM python:3.8
# Set the working directory, future commands are executed here
WORKDIR /app
# Add the requirements file to the docker image
ADD requirements.txt /app/requirements.txt
# Install the requirements
RUN pip3 install -r requirements.txt
# Add the rest of the files
ADD . /app
# Expose port 5000 of container
EXPOSE 5000
# Run the python app with argument "app.py"
CMD [ "python", "app.py"]
Model hunt
Initially I thought of finding a pre-trained model on git, since there was no time to train one (considering the accuracy/time tradeoff) and using it in a flask server.
So, I chose DistilBert for this task since it is accurate enough for sentiment analysis and lightweight (260mb, smaller compared to other famous language models).
Model Implementation
Then came the giant task of implementing this model, why is it difficult you’d ask? First we need to add all the dependencies to run the model, then filter/format the incoming data and feed it into the model, and finally format the output.. which is difficult to do if you have no idea what the model takes as an input (this was pre ChatGPT era, so couldn’t go for the easy solution).
It was during this research that I found huggingface and it was love at first sight… Oh, the ease with which one could implement models using their transformers. Changing the model is just a single line change, no need to go change the whole input and output format.

Hugging face
Currently it’s an open source ML/AI community, a great combination.
Next I needed to find a way for abusive content detection, at the time of writing, Detoxify is the most popular transformer used for it.
Creating the inference endpoint
The initial version of the inference endpoint was just running the two classifiers sequentially on the input from the API
from detoxify import Detoxify
from transformers import pipeline
# Initialize the classifiers - Change the model names here if needed
sentimentClassifier = pipeline("sentiment-analysis")
abusiveClassifier = Detoxify("original")
@app.route("/", methods=["POST"])
def inference_engine():
# Get the input data from the POST request
inputData = request.get_json()["modelInput"]
# Pass the input data to the classifiers
abusiveResult = abusiveClassifier(inputData)
sentimentResult = sentimentClassifier(inputData)
print(sentimentResult, flush=True)
print(abusiveResult, flush=True)
# Return the result as a response
return jsonify(
{"sentimentAnalysis": sentimentResult, "abuseAnalysis": abusiveResult}
)
# Run the flask app
but the response times were too long. So like any software development process I had to iterate again for improvement.
But first I needed to get to the root of this issue and find the step taking the most time. Logging each step is the way I did this.
What I found was that most of the time was spent on classifying the texts, understandable but I was sure it could be optimized.
Optimization
One way of optimization may be a lighter model but there might be an accuracy tradeoff, also hunting for a model and changing the implementation (I couldn’t find a replacement on hugging face at the time) is not a good use of the limited time.
Another way to make the classification faster is to run them in parallel (If your machine supports and has the bandwidth for it).
Currently the flask server has to listen to the requests, compute the sentiment and abuse analysis, all on the same thread sequentially. There should be a significant speedup by using multiple threads/processes for classification.
Now to decide what to use - Multithreading or Multiple processes - well the choice was already made for us as soon as we used python for the API. That is - multiple processes!!
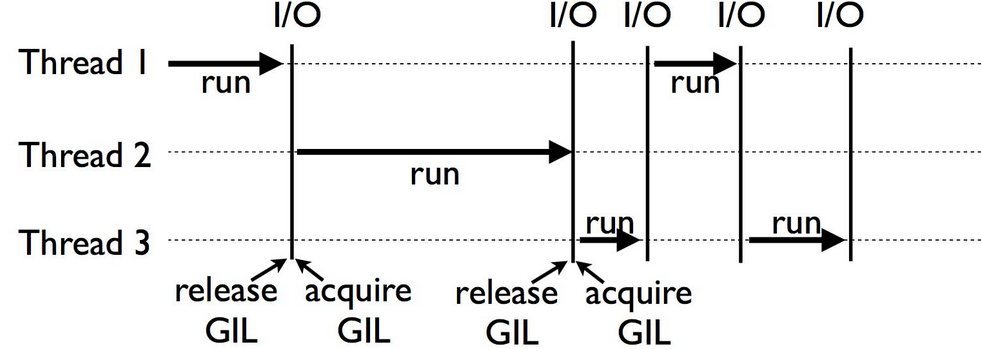
The next thread only runs when the current thread is IO/network blocked
In the python interpreter there is a Global Interpreter Lock (GIL) which ensures that only one thread runs in the interpreter at once. For a detailed explanation of GIL, read this presentation So for CPU intensive applications multiple processes are the only choice…
So, lets say we made 2 processes, then we need to setup communication between them. There are 2 methods to achieve this, shared memory or message passing, I chose to communicate through queues (message passing). Since I didn’t know how to use locks in python and because Queues are easier to implement and manage.
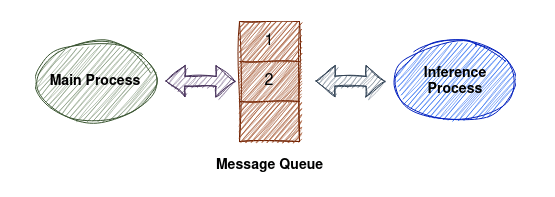
Since this was running on a local machine with great specs, there was no need to consider if the machine could handle the 2 models inferring at once.
So I ran 2 processes with a check if they are down
sentimentProcess = None
abusiveProcess = None
def process_restart():
if sentimentProcess is None or not sentimentProcess.is_alive():
sentimentProcess = Process(
target=sentiment_worker(queue), args=(sentimentQueue,)
)
sentimentProcess.start()
if abusiveProcess is None or not abusiveProcess.is_alive():
abusiveProcess = Process(target=sentiment_worker(queue), args=(abusiveQueue,))
abusiveProcess.start()
and fed the request input to the processes through a queue.
sentimentQueue.put(inputData)
abusiveQueue.put(inputData)
Then gave the response back to the main process through the same queue
Final program
from flask import Flask, request, jsonify, Response
from detoxify import Detoxify
from transformers import pipeline
from multiprocessing import Process, Queue
app = Flask(__name__)
sentimentClassifier = pipeline("sentiment-analysis")
abusiveClassifier = Detoxify("original")
sentimentProcess = None
abusiveProcess = None
sentimentQueue = Queue()
abusiveQueue = Queue()
def sentiment_worker(queue):
while True:
# Wait for input from the queue
inputData = queue.get()
# Perform the ML inference on inputData
result = sentimentClassifier(input)
# Put the result in the queue for Flask to retrieve
queue.put(result)
def abusive_worker(queue):
while True:
# Wait for input from the queue
inputData = queue.get()
# Perform the ML inference on inputData
result = sentimentClassifier(input)
# Put the result in the queue for Flask to retrieve
queue.put(result)
# If the processes are not running, start them
def process_restart():
if sentimentProcess is None or not sentimentProcess.is_alive():
sentimentProcess = Process(
target=sentiment_worker(queue), args=(sentimentQueue,)
)
sentimentProcess.start()
if abusiveProcess is None or not abusiveProcess.is_alive():
abusiveProcess = Process(target=sentiment_worker(queue), args=(abusiveQueue,))
abusiveProcess.start()
@app.route("/", methods=["POST"])
def inference_engine():
# Get the input data from the POST request
inputData = request.get_json()["modelInput"]
process_restart()
# Pass the input data to the processes through the queue
sentimentQueue.put(inputData)
abusiveQueue.put(inputData)
# Wait for the result from the processes
abusiveResult = abusiveQueue.get()
sentimentResult = sentimentQueue.get()
# Return the result as a response
print(sentimentResult, flush=True)
print(abusiveResult, flush=True)
return jsonify(
{"sentimentAnalysis": sentimentResult, "abuseAnalysis": abusiveResult}
)
The End
That’s all folks!! I stopped working on the app as I almost fell out of my chair from sleep deprivation and sometime later we gave the presentation for this idea. Though we didn’t win any prizes, I was amazed that I could implement all this in under a day (Without ChatGPT).
“In the end we retain from our studies only that which we practically apply.”— Johann Wolfgang Von Goethe
Post notes
- There are other lighter alternatives for sentiment analysis like MobileBert (90mb), it is easy to replace the model if needed.
- Detoxify also has lightweight models like
original-smalletc, which can be changed as well - Running both models at once might hit the RAM limits on hosted machines
- Github Link
Leave a comment